|
My name is Chenghao Li, and I often use the name Shenghao Li in my publications. I just graduated with a Ph.D. from Shanghai Jiao Tong University (SJTU), where I work on 3D Vision, Local Feature Learning, and Scene Representation and Understanding. I was advised by Prof. Qunfei Zhao. From 2021 to 2023, I was very fortunate to work with Dr. Junjie Yan and Dr. Bin Yang on 3D animatable avatars and text-to-image generative models. I did my MS and BS in Mechatronics at the Intelligent Robot Lab, part of the School of Mechanical and Power Engineering at ECUST. My adviser was Prof. Shuang Liu, and I worked on several projects in computer vision and robotics, including VSLAM, object detection, object tracking, etc. I participated in multiple internships throughout my Ph.D. and MS. I was an intern at MiniMax, where I worked on computer vision algorithms for 3D animatable avatars and large vision-language models for text-to-image generation. Additionally, I interned at Qualcomm as an AI engineer for mobile computing and at Oceanbotech as a robotic vision engineer. Please feel free to email me to discuss computer vision, robotics, AGI, etc. |

|
|
|
|
I'm interested in computer vision, machine learning, optimization, and image processing. Much of my research is about scene reconstruction and representation from images or videos. Representative papers are highlighted. |

|
Shenghao Li, Zeyang Xia, Qunfei Zhao* IEEE Transactions on Circuits and Systems for Video Technology, 2023. paper project page We propose a novel online scene representation method to address the issues of unknown camera poses, boundary ambiguity, and observation noises (camera motion blur). The proposed method can produce sharp and compact representations of scenes under various shooting conditions. |

|
Shenghao Li, Qunfei Zhao* Zeyang Xia, IEEE Transactions on Image Processing, 2023. paper code We propose a novel sparse-to-local-dense (S2LD) matching method to conduct fully differentiable correspondence estimation with the prior from epipolar geometry. The sparse-to-local-dense matching asymmetrically establishes correspondences with consistent sub-pixel coordinates while reducing the computation of matching. The salient features are explicitly located, and the description is conditioned on both views with the global receptive field provided by the attention mechanism. The correspondences are progressively established in multiple levels to reduce the underlying re-projection error. |
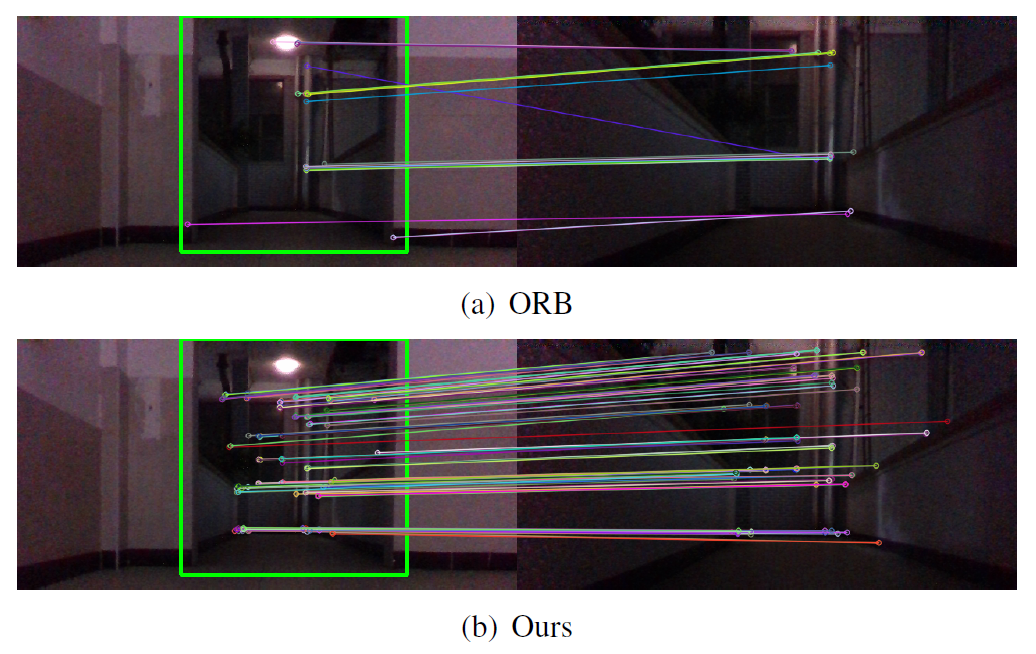
|
Shenghao Li, Shuang Liu* Qunfei Zhao Qiaoyang Xia, IEEE/ASME Transactions on Mechatronics, 2022. paper We propose a quantized self-supervised local feature for the indirect VSLAM to handle the environmental interference in robot localization tasks. |
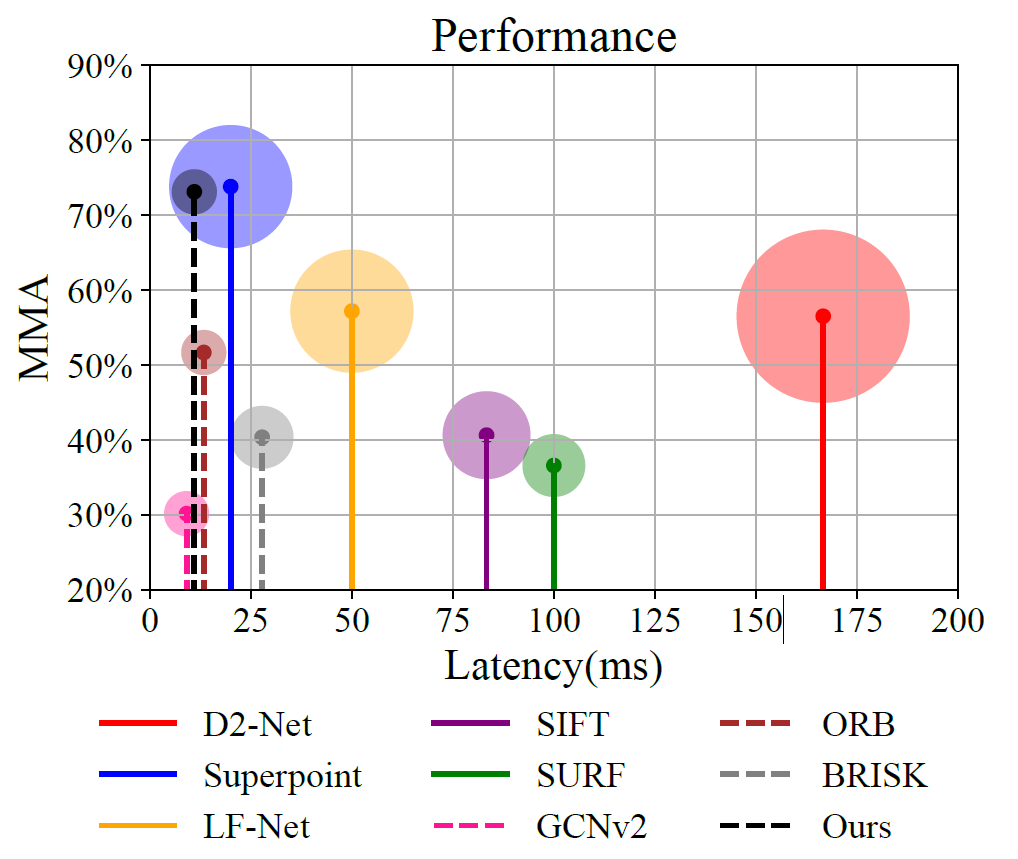
|
Shenghao Li, Guibao Zhang, Qunfei Zhao* IEEE International Conference on Real-time Computing and Robotics (RCAR), 2021. paper We proposes a single-input multi-output model for feature extraction and a descriptor quantization approach to embedding the features into Hamming space. |
|
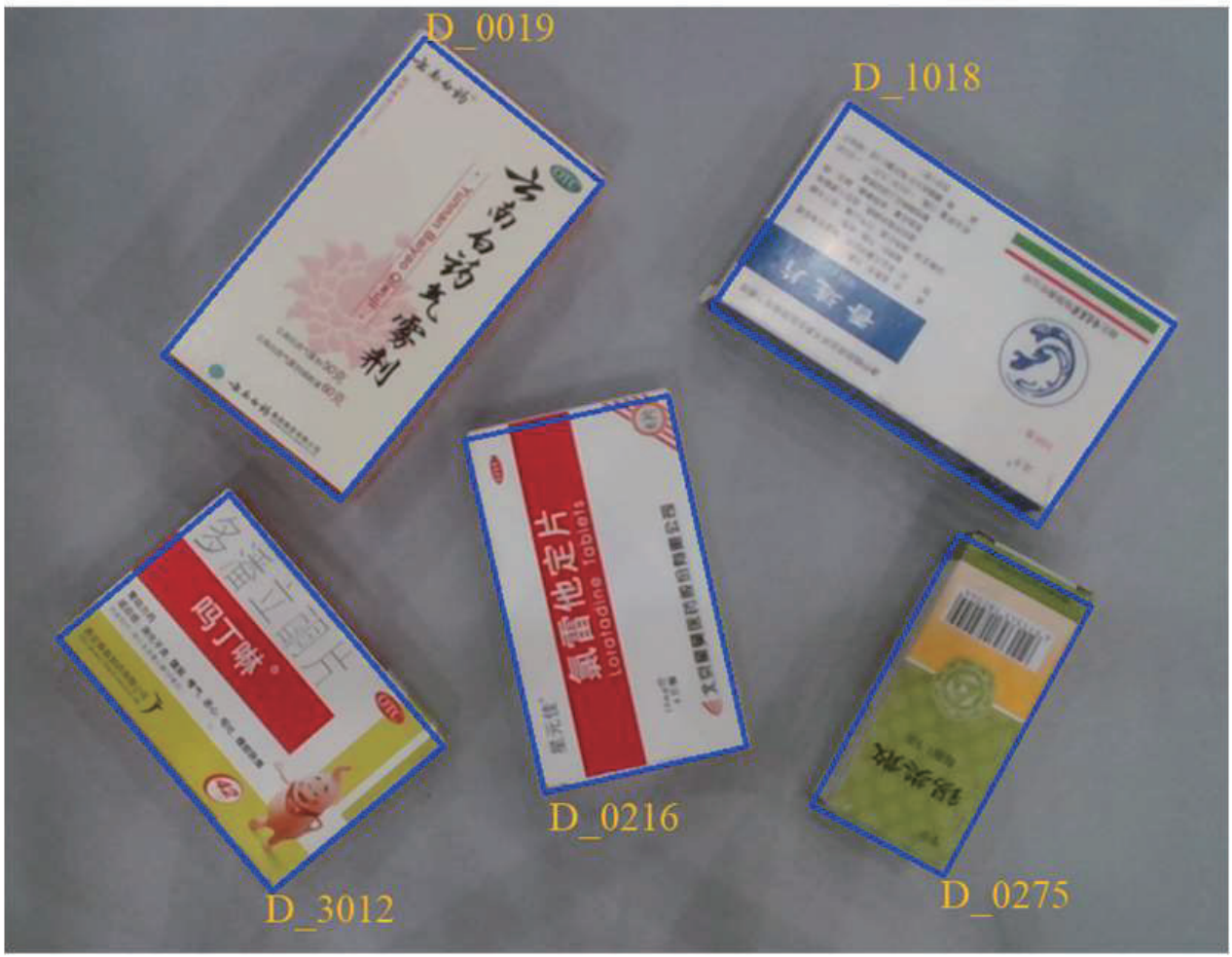
Changzheng Zhang, Qiaoyang Xia, Shenghao Li, Simeng Zhong, Shuang Liu*, International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), 2021. paper We propose an automatic drug box detection method based on the gemoetry and color priors of the drug boxes observed from an RGB-D camera. |
|
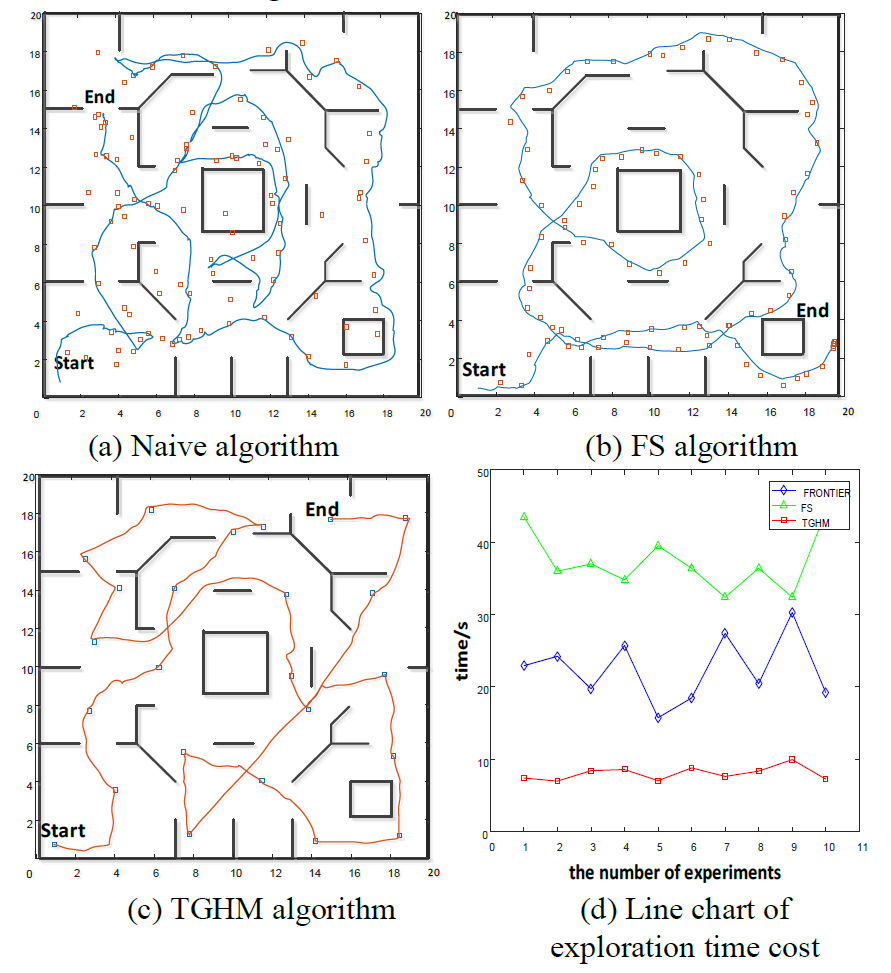
Shuang Liu, Shenghao Li, Luchao Pang, Jiahao Hu, Haoyao Chen* Sensors, 2020. paper We proposes proposes an autonomous exploration and map construction method based on an incremental caching topology-grid hybrid map (TGHM). |

|
Shenghao Li, Shuang Liu*, Qiaoyang Xia, Hui Wang, Haoyao Chen, IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), 2019. paper We propose an automatic container code localization and recognition system via an efficient code detector and a sequence recognizer. |
|
Here are some of my research and industrial projects. More open-source code will be available soon on Github. |

|
code We developed an open-source Intelligent mobile platform with mecanum wheels. This platform is equipped with a RGB-D camera, a 2D LiDAR, IMU, odometry, etc. Features like Gazebo simulation, 2D SLAM, Visual SLAM, object tracking, navigation, and autonomous driving are available in this package. |

|
We developed a vision-based workpiece grabbing algorithm with a line-scan camera and a multi-truss system for industrial deployment. |
|
|
During my internship at MiniMax, I helped establish a pipeline for creating animatable avatars driven by facial keypoints. Since this project is licensed, a new version will be coming soon. |
|
The templet of this page is from Jon Barron. |